Large Language Models
Spice provides a high-performance, OpenAI API-compatible AI Gateway optimized for managing and scaling large language models (LLMs). It offers tools for Enterprise Retrieval-Augmented Generation (RAG), such as SQL query across federated datasets and an advanced search feature (see Search).
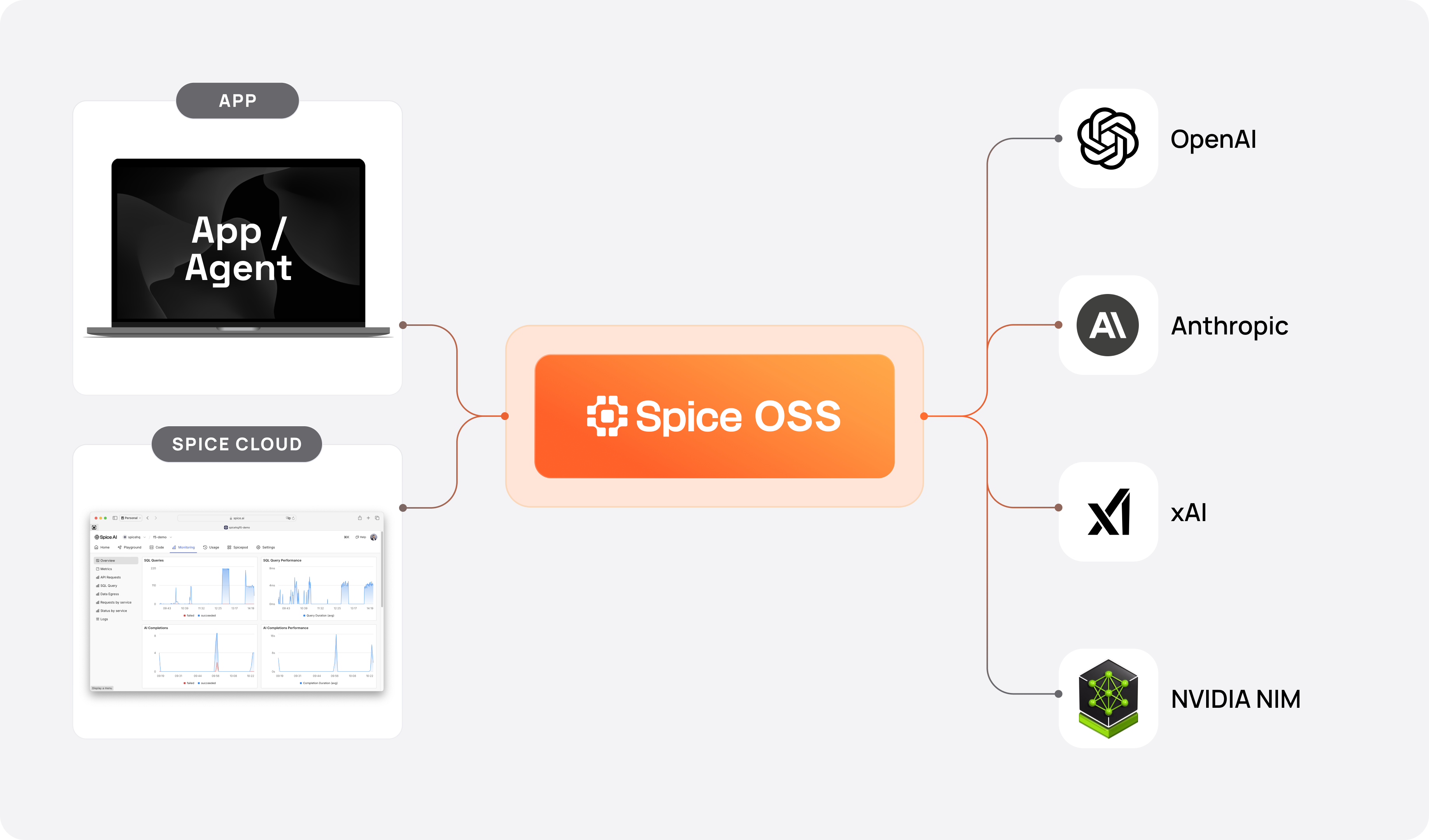 .
.
Spice supports full OpenTelemetry observability, helping with detailed tracking of model tool use, recursion, data flows and requests for full transparency and easier debugging.
Configuring Language Models
Spice supports a variety of LLMs (see Model Providers).
Core Features
- Custom Tools: Provide models with tools to interact with the Spice runtime. See Tools.
- System Prompts: Customize system prompts and override defaults for
v1/chat/completion. See Parameter Overrides. - Memory: Provide LLMs with memory persistence tools to store and retrieve information across conversations. See Memory.
- Vector Search: Perform advanced vector-based searches using embeddings. See Vector Search.
- Evals: Evaluate, track, compare, and improve language model performance for specific tasks. See Evals.
- Local Models: Load and serve models locally from various sources, including local filesystems and Hugging Face. See Local Models.
For API usage, refer to the API Documentation.
📄️ Tools
Learn how LLMs interact with the Spice runtime.
📄️ Memory
Learn how to provide LLMs with memory
📄️ Evals
Learn how Spice evaluates, tracks, compares, and improves language model performance for specific tasks
📄️ Parameter Overrides
Learn how to override default LLM hyperparameters in Spice.
📄️ Local Models
Learn how to load and serve large learning models.
